Big Data, o l’analisi dei dati quando N=all

Il termine “Big Data” è da tempo entrato nel vocabolario comune: lo si sente associato alla ricerca medica, alle funzionalità di Google, e pure alla manutenzione dei tombini di New York. Ma mi sono reso conto, riflettendoci, che avevo un’idea alquanto vaga e confusa di ciò che il termine implica effettivamente.
Questa, secondo me, è una caratteristica dei Big Data: capire cosa sono realmente è difficile, perché semplicemente sono ovunque (no, tranquilli, non sono un complottista non ancora). Allora ho voluto informarmi più approfonditamente sull’argomento, e quale migliore occasione per scrivere un articolo?
Il termine “big data” (con le minuscole) nasce come definizione per i database contenenti una tale mole di dati da rendere inefficiente l’applicazione delle tecniche “classiche” di analisi dei dati e richiedere grandi potenze di calcolo.
Concettualmente poi, il termine si è esteso (e infatti ha conquistato le iniziali maiuscole) ad indicare tutto l’insieme di tecniche di analisi, applicazioni, sorgenti di dati e molto altro che gravita attorno a questi enormi database.
Una definizione di Big Data fra le più comprensive è forse quella proposta in (De Mauro et al., 2014):
Big Data represents the Information assets characterised by such a High Volume, Velocity and Variety to require specific Technology and Analytical Methods for its transformation into Value.
Analizziamo un attimo questa definizione:
- “Big Data represents the Information assets characterised by such a High Volume, Velocity and Variety”. Informazione: la base di tutto sono database (pun intended) di ampiezza enorme, velocità elevata (nel senso che spesso sono disponibili in tempo reale) e varietà (nel senso che non si compongono di entries strutturate e ben definite).
- “to require specific Technology and Analytical Methods”. Tecnologia: senza la disponibilità di memorie di massa ad alta densità, dimensioni ridotte ed economiche, i Big Data non sarebbero possibili (nemmeno sarebbero nati). Metodi: non è possibili utilizzare tecniche di analisi dei dati classiche ai Big Data, è necessario sviluppare nuovi strumenti di analisi.
- “for its transformation in Value”. L’Impatto che l’analisi di Big Data ha, rappresenta il suo valore.
Bene, ora che abbiamo inquadrato il concetto di Big Data, vediamo i cambiamenti messi in atto dal loro utilizzo. Il rinnovamento tocca principalmente tre assunti del metodo di analizzare l’informazione (scusate, mi piacciono troppo gli elenchi puntati):
- la dimensione dei database disponibili (ma dai!): non è più necessaria infatti la scelta accurata dell’insieme di dati da analizzare, ora è possibile prenderli tutti in considerazione. Grazie all’innovazione tecnologica della potenza di calcolo, della memoria e dei sensori (intesi come sistemi di raccolta dei dati) cade la necessità di ‘campionare’.
- La qualità dei dati: non è più necessario richiedere che i dati siano estremamente precisi. Quando se ne può analizzare una quantità enorme, un pò di imprecisione è un piccolo prezzo da pagare.
- La caduta della causalità: è normale per noi uomini cercare di descrivere i fenomeni che analizziamo con una serie di relazioni causa-effetto. I Big Data invece basano i propri risultati sulla correlazione; non ci dicono perchè qualcosa avviene, ma ci avvertono di cosa avviene.
Nelle prossime tre sezioni vediamo di analizzare un po’ questi cambiamenti e le loro conseguenze, il tutto condito di esempi.
Più dati
L’avvento dei Big Data è stato possibile solo grazie al progresso tecnologico: degli strumenti per la raccolta dei dati, delle risorse di calcolo e della quantità di memoria disponibile. Per capire il significato di questa affermazione basta pensare al censimento del 1880 negli Stati Uniti: sono stati necessari 7 anni per tabulare tutti i dati raccolti e analizzarli. Questo problema sembra quasi triviale grazie alle risorse di calcolo disponibili attualmente, ma al tempo era un grande limite.
In passato sono state sviluppate moltissime tecniche per aggirare l’ostacolo posto dal limite tecnologico. La statistica è praticamente nata con questo fine e i suoi strumenti hanno raggiunto precisione e raffinatezza sorprendenti. La possibilità di dedurre risultati molto verosimili analizzando solo un campione randomizzato di misurazioni ha reso possibile lo sviluppo scientifico che ha portato ai giorni nostri.
Grazie ai Big Data, però, decade questa necessità di campionare (che si tratti di selezionare solo alcune misurazioni in un esperimento, fare un censimento di solo una frazione della popolazione, ecc.).
I Big Data rendono chiara la vera natura del campionamento: è una scorciatoia per poter aggirare il bottleneck tecnologico, ottenendo risultati con un margine d’errore accettabile. Ma ora non è più necessario prendere questa scorciatoia. Il vantaggio di questo è nella versatilità dell’analisi che si può intraprendere sui dati. Mi spiego utilizzando l’esempio del censimento.
Uno Stato interessato a censire la propria popolazione probabilmente preparerà dei questionari, in funzione delle domande cui si propone di rispondere (come: qual è il livello di benessere economico dei cittadini?) e li sottoporrà a un campione casuale di popolazione.
È un buon sistema, perché grazie alla statistica i risultati ottenuti sono molto precisi e con un margine di errore davvero ridotto. Ma se poi il signor Tizio Caio, dipendente dell’ufficio demografico, decide che vuole sapere come se la passa dal punto di vista economico solo la popolazione maschile?
Va bene, si può fare: d’altronde metà del campione analizzato è composto da uomini, e lo scopo del questionario era quello. Però se Tizio volesse sapere come stanno le tasche delle donne che vivono nel quartiere Tale o nella via Talaltra? I dati raccolti non sono chiaramente più sufficienti, dato che di persone che corrispondono al profilo ne hanno intervistate solo due, e ce ne sarebbero 200 altre in quel quartiere.
E poi, se per caso si volesse sapere quale parte della cittadinanza legge un libro prima di andare a dormire? “Beh, impossibile saperlo”, risponde Tizio Caio, “non c’era mica la domanda nel questionario!”

E se invece di intervistare solo un campione, lo Stato avesse accesso, tramite diversi intermediari, a una quantità di dati così vasta da poter censire quasi tutta la sua popolazione?
Sembra impossibile, ma così non è: basta pensare a cosa si può trovare sui social network, ai dati raccolti dalle compagnie telefoniche ecc. (la paranoia sale). A questo punto Tizio Caio può farsi tutte le domande che vuole: un database così vasto permette un’analisi granulare e di grande precisione.
E risulta possibile anche cercare di capire quante persone leggono la sera, o quante guardano la TV, e via dicendo. Per una volta quel pignolo e maniaco del controllo di Tizio Caio va a casa contento, e magari smetterà anche di perdere i capelli.
Un’ultima precisazione che mi preme fare: si parla di Big Data, e big vuol dire grande; però questa definizione non deve trarre in inganno. Con Big Data si intende la disponibilità di tutto l’insieme dei dati, non solo di una sua parte.
Ad esempio nell’analisi fatta da Steven Levitt in ‘Freakonomics’ alla ricerca di incontri di sumo truccati, il database utilizzato di 11 anni di risultati occupava meno di una foto digitale (scusate non ho trovato il quantitativo in kB, chiedo venia). Però comprendeva tutti gli incontri che si potesse analizzare di quei undici anni.
Il punto, quindi, è che i Big Data danno all’analisi dei dati due strumenti potentissimi: la versatilità (cioè la possibilità di dedurre risultati diversi da quelli che si voleva ottenere alla raccolta dei dati) e la granularità (cioè la capacità di analizzare nel dettaglio i dati senza perdere di precisione).
Messy is good enough
Nel paragrafo precedente ho fatto l’esempio di dati raccolti grazie a un social network, riflettendo un attimo ci si accorge però di un problema.
Su un social network ci sono: stringhe di testo che non rispettano nessun format (e spesso nemmeno grammaticalmente corrette), immagini, video, ‘mi piace’ di Facebook, cuori di Instagram o stelline di Twitter, hashtag e via discorrendo. La differenza con i database di tipo relazionale, legati ad una struttura fissa è abissale.
Nel suo articolo ‘If you have too much data, then “good enough” is good enough’ Pat Helland riassume in una bella e concisa lista il cambiamento dai database SQL a quelli di tipo noSQL (not only SQL), ovvero da dati ordinati a dati messy:
- Unlocked data: i dati vivono in un ecosistema di inesattezza. In una rete distribuita di calcolatori, il dato richiesto da B, potrebbe subire cambiamenti anche il millisecondo successivo all’invio da parte di A. I dati non sono più chiari ed immutabili.
- Inconsistent schema: non c’è un formato ben definito per i dati che ricevi, molto spesso la descrizione della semantica utilizzata per interpretarli viene allegata direttamente al dato. Questa tecnica però è aperta ad errori, interpretazioni non esatte e incomprensioni. Però è scalabile e permette di inferire le informazioni necessarie da una vasta mole di dati.
Un esempio molto calzante è quello degli stereotipi associati al modo di vestire. In una città in cui vive un grandissimo numero di benemeriti sconosciuti, dedurre alcune importanti informazioni riguardo i passanti che incontri solo guardando cosa indossano può essere un grande vantaggio. Si tratta pur sempre di stereotipi, i dati che ricavi nel vedere Tizio A con un completo o Tizio B con dei jeans strappati possono non essere precisi, ma servono la loro funzione. - Extract, transform and load: l’eterogeneità dei dati e delle loro fonti richiede una certa manipolazione per poterli analizzare ed estrarne valore. Tuttavia questo procedimento è molto spesso di tipo ‘lossy’, cioè non è possibile tornare al dato di partenza, ma nel frattempo la tua analisi ha prodotto risultati utili.
- Patterns by inference: sono necessari potenti strumenti come gli ‘inference engines’ per poter inferire da una messe di dati caotica relazioni che li uniscano.
- Too much to be accurate: la variabilità dei dati e la velocità con cui i cambiamenti avvengono costringe a fare i conti con una buona dose di approssimazioni.
Abbiamo visto che i Big Data possono essere disordinati, inaccurati, senza schema, imprecisi e chi più ne ha più ne metta. Questo è appunto un cambiamento rispetto al mondo degli small data, in cui invece i pochi dati disponibili su cui basare l’analisi dovevano essere per forza di cose precisissimi.
Avviene una sorta di scambio: aprendo a quantità maggiori di dati si apre all’inesattezza, ma in cambio si ottengono risultati di grande valore. Si pensi ad esempio a Flickr: catalogare le immagini che gli utenti condividono sarebbe un compito impossibile per i progettisti del sistema.

Chi potrebbe immaginare che la categoria “Gatti che assomigliano a Hitler” possa mai esistere? Quindi lasciando all’utente la possibilità di ‘taggare’ le proprie foto liberamente, il sito risolve il problema.
Certo, i tag non sono tutti standardizzati, si infiltrano errori grammaticali, slang diversi e varie altre fonti di imprecisioni. Ma è possibile cercare con grande accuratezza le immagini e navigare fra di esse. Di fatto i tag sono diventati lo standard per la catalogazione dei contenuti di tipo non testuale su Internet.
Certo, il database delle transazioni sui conti correnti gestiti da una banca non potrà mai adeguarsi a trattare con dati imprecisi. Ma per molte applicazioni l’inaccuratezza è un prezzo che vale la pena pagare.
Causalità vs Correlazione
La nostra mente è plasmata sulla ricerca di relazioni causa-effetto fra i fenomeni cui assistiamo. Se per esempio dico: “I genitori di Franco sono in ritardo. Fra poco arriva il catering.
Franco è arrabbiato”, immediatamente capiamo che Franco è arrabbiato per il ritardo dei suoi genitori (liberamente tratto da un esempio di Daniel Kahneman). Ma in realtà non abbiamo nessun dato per confermare la nostra intuizione. Franco potrebbe aver visto la sua ex per strada con un tizio in carne e sudaticcio – per fortuna che non le piaceva la mia pancetta.
Nell’ambito dei Big Data è invece la correlazione a fare da padrona. Gli strumenti di analisi basati sulla ricerca di correlazioni fra i dati sono fra i più potenti nel campo, alla base ad esempio del sistema di raccomandazioni di Amazon (e non dite che non c’azzecca). In sostanza la correlazione quantifica la probabilità che quando accade A, segua B.
La correlazione non è certezza, ma solo una relazione statistica fra due o più dati che emerge dall’analisi.

Queste tecniche venivano utilizzate anche nel mondo degli small data, ma con una differenza. Prima di procedere con un esperimento (ad esempio) viene fatta un’ipotesi, basata sull’esperienza dello scienziato.
Vengono raccolti i dati e si esegue l’analisi: questa prova se l’ipotesi è vera o falsa. Nel caso sia falsa se ne formula un’altra e si ripete la procedura. La verifica di una teoria segue quindi un processo di trial-and-error anche molto laborioso.
Nel mondo dei big data la correlazione si libera dalle ipotesi iniziali: l’analista decide la direzione in cui vorrebbe che l’algoritmo esegua la sua ricerca, e i risultati parlano da se. Molto spesso è il programma in se che procede a formulare (anche milioni) di modelli matematici e testarli sulla mole dei dati disponibili.
Questo produce poi risultati in modo, diciamo, autonomo. Non ci dice perchè una cosa succede, non ci spiega le cause di un fenomeno, ma, analisi dei dati ‘alla mano’, esclama: “Se succede A allora molto probabilmente B, ho trovato una correlazione con probabilità tot.”.
Per noi un’affermazione del genere potrebbe sembrare controintuitiva. Sostituite ad esempio ad A: ‘quando c’è un uragano in arrivo’ e a B: ‘le Pop-Tarts vendono benissimo’. Perchè?!?!?!?! Eppure questo è uno dei risultati prodotti dalla ricerca di correlazioni eseguita da Wal-Mart nel 2004 sul database delle sue transazioni. Utilizzare i Big Data in questo modo richiede sicuramente un certo tempo per abituarsi.
 Fra gli strumenti basati sulla correlazione spicca la ‘predictive analytics‘: una tecnica che permette di sfruttare le relazioni probabilistiche come un campanello di allarme per il verificarsi di dati avvenimenti.
Fra gli strumenti basati sulla correlazione spicca la ‘predictive analytics‘: una tecnica che permette di sfruttare le relazioni probabilistiche come un campanello di allarme per il verificarsi di dati avvenimenti.
Due esempi sono il monitoraggio dei ponti: un gran numero di sensori installati sulla struttura identifica gli schemi che portano a un cedimento.
E il controllo dell’usura nelle vetture: i sensori installati su componenti chiave, come il motore o gli assi, permette di capire quando è più probabile che un guasto avvenga. In entrambi i casi è possibile agire anzitempo, prevenendo il problema. Tutto solo sapendo che se A allora probabilmente B.
Datafication
Le applicazioni Big Data sono sempre più voraci di dati: si processano più informazioni, più velocemente, in più modi; i dati sono la loro benzina. Ed ecco che entra in gioco la ‘Datafication’. Si considera datafication il processo di trasformare in dati da cui estrarre valore qualsiasi cosa che sia misurabile, tracciabile, taggabile ecc. Mi spiego meglio con un esempio.
Chi potrebbe pensare che il nostro sedere possa funzionare come una ID? Il signor Shigeomi Koshimizu, professore dell’AIIT di Tokyo! Nella sua ricerca del 2009 ha dimostrato che l’impronta del lato B di una persona può essere utilizzata per identificarla con il 98% della precisione.
L’applicazione pensata da Koshimizu è di utilizzare questa conoscenza nel progettare sedili delle auto che facciano anche da antifurto. O che si accorgano, dai cambiamenti nella postura del guidatore, del suo stato di allerta o sonnolenza. Si tratta proprio di datafication: prendere qualcosa fino ad ora mai considerato come ‘dati’ ed estrarne valore analizzandolo.
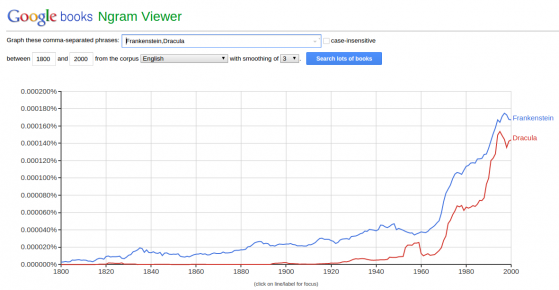
Un altro esempio è quello fornito da Google Ngram Viewer. Conosciamo tutti il mastodontico progetto di digitization Google Books, che ha scannerizzato milioni di libri editi dal 1800 al 2000. Questo di per se non è molto diverso da campionare un segnale analogico (audio, per dirne uno) e memorizzarlo su un computer.
Ma il progetto Ngram Viewer va oltre: infatti permette di analizzare la frequenza con cui i termini cercati dall’utente appaiono nei libri e tracciare un grafico. Google ha preso libri cartacei, li ha digitalizzati e poi dataficati.
The dark side of Big Data
Ho deciso di chiudere l’articolo con alcuni spunti di riflessione che spero vorrete discutere con me nei commenti qui sotto. Si tratta degli argomenti più scottanti dal punto di vista legislativo e sociale riguardanti i Big Data.
Buoni, cattivi, neutrali? Dipende.
I Big Data sono buoni, cattivi o neutrali? Come dicono (Boyd & Crawford, 2012): dipende. A partire dalla loro raccolta, passando per l’analisi e arrivando all’interpretazione dei risultati, sta tutto nella visione dell’analista. I ‘pregiudizi’, la volontà di dimostrare a tutti i costi una correlazione, sono tutti possibili bias, che inficiano il corretto utilizzo dei dati.
Quindi in se le tecniche di analisi devono essere a prova di errore e pregiudizio umano per risultare effettivamente solide. Gli autori di “Big Data: a revolution that will transform how we live, work, and think” suggeriscono che per far fronte a utilizzi scorretti e illegali
(dovendo anche definire cosa si intende per ‘illegali’) sia necessario formare le figure degli ‘Algorithmists‘. Una specie di super avvocati con una solida preparazione informatica che vagliano gli algoritmi e il modo di utilizzarli.

Algorithmists: io me li immagino così
Minority Report diventa realtà
Ma ci sono già alcune dimostrazioni dell’utilizzo ‘illegale’ o, diciamo, borderline, di questi strumenti così potenti. Alcuni ricercatori hanno potuto risalire all’identità di un singolo individuo combinando alcuni database pubblicamente accessibili, come quello anonimizzato delle statistiche degli utenti Netflix e di un sito per recensire i film (scusate non riesco a ritrovare l’articolo).
Per fare un esempio che gradirete: la distopia di Minority Report potrebbe diventare realtà. Alcune forze di polizia (americane ma non solo) stanno già studiando la possibilità di prevedere comportamenti illegali e agire prima che si verifichino grazie all’analisi di dati dei social network e altri fattori.
Il marketing aggressivo
È successo a tutti di cercare qualche articolo su Amazon e poco dopo essere bombardati da una serie di articoli correlati nelle pubblicità dei siti visitati.
I Big Data rendono questo e molto altro possibile: pubblicità mirate e personalizzate grazie all’analisi di tutta la serie di tracce digitali che ogni utente si lascia alle spalle su Internet.
Assicurazioni e prestiti
Tramite i Big Data è possibile anche analizzare la possibilità che una persona sia un buon debitore o che sia particolarmente a rischio di malattie come il diabete. Tutto questo tramite l’analisi della storia finanziaria e medica e grazie a modelli dedotti dall’analisi Big Data.
Molte aziende di consulenza si sono già specializzate in questo campo, fornendo ad agenzie assicurative e banche probabili profili dei propri clienti. Ma è giusto negare un prestito al signor Mario Verdi sulla base della correlazione?
Il Grande Fratello
La polizia di Minority Report è poca cosa a confronto con lo Stato onnipresente e onniscente, il Grande Fratello in 1984 di Orwell. I Big Data rendono, in linea teorica, possibile anche questo: un controllo capillare dei cittadini in ogni aspetto della loro vita.
Uno Stato che potesse aggregare i dati dei gestori telco, dei social network, finanziari e di geolocalizzazione delle persone sarebbe molto vicino al GF. Ma Snowden non dice che è già successo?!
La ricerca sul cancro
Non ci si presentano però solo scenari apocalittici. La ricerca sul cancro e in genere la ricerca in ambito medico, il cambiamento climatico e molte altri studi ricevono un grande impulso dai Big Data. E abbiamo visto come possono essere utilizzati anche per prevenire guasti sulle auto e nelle strutture. E molte applicazioni permettono uno studio approfondito di fenomeni che ci era precluso prima dell’avvento dei Big Data.
Bene, ora che immagino sarete più o meno così:

lascio a voi la parola nei commenti per discutere i pro e i contro di questa tecnologia!
- Critical questions for Big Data: provocations for a cultural, technological, and scholarly phenomenon. Boyd D., Crawford K. 2012
- Big Data: a revolution that will transform how we live, work, and think. Mayer-Schonberger V., Cukier K. 2013
- If you have too much data, then “good enough” is good enough. Helland P. 2011
- What is Big Data? A consensual definition and a review of key research topics. De Mauro A, Greco M., Grimaldi M. 2014
- Big Data For Dummies. Alan Nugent, Fern Halper, Marcia Kaufman