
Introduzione al Natural Computing

“Ma cosa c’entrano natura e computer?” È la legittima domanda che potreste esservi posti leggendo il titolo. D’altronde il computer è tipicamente considerato un oggetto artificiale, una creazione – fra le più raffinate – dell’uomo. In questo articolo, invece, vi dimostrerò che natura e Informatica hanno molto in comune: parlandovi del Natural Computing.
in questo articolo userò il nome inglese Natural Computing invece dell’italiano Computazione Naturale; proprio non mi piace come suona.
Per rompere il ghiaccio, vediamo quali sono alcuni argomenti trattati dal natural computing. Avrete sentito tutti parlare di reti neurali, grazie alla diffusione di cui godono ormai le tecniche di Intelligenza Artificiale.
Le reti neurali sono di fatto una delle primissime teorie informatiche ispirate dalla natura: ricadono quindi a buon diritto nell’ambito del natural computing. A queste si affiancano poi gli algoritmi genetici, che mimano il processo evolutivo delle specie biologiche per risolvere problemi di ottimizzazione. Altri esempi sono gli automi cellulari, il quantum computing e la swarm intelligence (scusate la fissa per i nomi inglesi, alcune traduzioni non si possono sentire).
L’obiettivo di questo articolo è descrivere brevemente il natural computing e parlare di alcuni ambiti di ricerca associati ad esso. L’argomento è davvero vasto e l’articolo non vuole tanto essere esaustivo, quanto fornire spunti per ulteriori ricerche su wiki approfondimenti.
Natural Computing: cos’è?
Cominciamo con ordine: cos’è il natural computing? Per spiegarlo rifacciamoci alla definizione presentata in [1]:
[…] natural computing can be defined as the field of research that, based on or inspired by nature, allows the development of new computational tools […] for problem solving, leads to the synthesis of natural patterns, behaviors, and organisms, and may result in the design of natural computing systems that use natural media to compute.
Dunque, vediamo subito che il natural computing ha un triplice scopo:
- lo sviluppo di nuovi algoritmi ispirati dall’osservazione e studio della natura; le già nominate reti neurali sono ispirate dalla Neuro-Anatomia, gli algoritmi genetici dalla Biologia e la swarm intelligence da Biologia ed Ecologia;
- la sintesi, cioè la simulazione, di particolari fenomeni naturali, come ad esempio le forme frattali (discussi brevemente nel mio articolo sulla Teoria del Caos) osservabili nel profilo delle coste, nei broccoli, nei nostri polmoni, ecc., o il comportamento degli organismi viventi (artificial life);
- la creazione di calcolatori (in senso lato, leggi: procedure per lo svolgimento di calcoli) utilizzando nuovi materiali naturali, in grado di affiancare o sostituire gli attuali computer con architettura basata sul silicio; si parla ad esempio di DNA computing e quantum computing.
Ad ognuno dei tre filoni di ricerca è dedicata un sezione dell’articolo. Per ogni sezione farò una breve introduzione e descriverò alcuni esempi. Le descrizioni degli esempi saranno concise, volte più a trasmettere l’idea di fondo che a fare una trattazione tecnica. Prima di proseguire, parliamo brevemente di alcune caratteristiche del natural computing nel complesso.

Natural Computing:
caratteristiche generali
Per prima cosa la multi-disciplinarietà: il natural computing nasce infatti dall’incontro fra Informatica e le Scienze Naturali, come ad esempio la Biologia, la Genetica e la Fisica.
Ma non è solo l’Informatica ad imparare dalle Scienze Naturali, è vero anche il viceversa. Il natural computing, infatti, fornisce utili strumenti per una maggiore comprensione della natura, tramite la simulazione computerizzata di fenomeni naturali. Di conseguenza solo dalla collaborazione tra biologi, informatici, ingegneri, fisici, chimici, per nominarne alcuni, il natural computing è reso possibile.
Bisogna poi notare che molti degli approcci di ricerca nel natural computing sono caratterizzati da un certo grado di semplificazione. Infatti al crescere dei dettagli inclusi nella simulazione di un fenomeno, cresce anche l’onere computazionale. Inoltre, concentrarsi su determinati aspetti particolari di un fenomeno può essere utile per evidenziare alcune proprietà emergenti.
Ispirazione dalla natura
La diffusione degli algoritmi di Intelligenza Artificiale ha reso questo settore del natural computing forse il più noto. Fanno capo a questo paradigma di ricerca, anche detto bio-inspired computing, le seguenti classi di algoritmi.
Reti neurali artificiali
Teorizzate per la prima volta da Warren S. McCulloch e Walter Pitts nel loro articolo del 1943 (vedi [6]), le reti neurali sono ispirate all’anatomia del cervello umano.
L’elemento di base delle reti neurali sono i neuroni, responsabili di processare le informazioni. Tali informazioni sono gli stimoli ricevuti tramite le sinapsi, ovvero i collegamenti con altri neuroni; ad ognuna di esse è attribuito un peso.
Un neurone, nel ricevere una serie di stimoli, ne valuta l’intensità, funzione dei pesi sinaptici. Se una determinata condizione è soddisfatta (ad es. la somma delle intensità supera una certa soglia) allora inoltra il ‘messaggio’, stimolando le sinapsi in uscita.
Neural Network Digital Art – Anastasiya Malakhova
I neuroni sono organizzati in livelli (layers): le uscite dei neuroni di un livello sono connesse agli ingressi del successivo. In base al numero di livelli e la complessità delle interconnessioni fra di essi cresce la potenza di calcolo della rete.
Fondamentale è inoltre l’algoritmo di apprendimento della rete: dopo la creazione della rete è infatti necessario aggiustare i pesi sinaptici per ottenere i risultati sperati. Un esempio è l’apprendimento supervisionato in cui vengono forniti alla rete una serie di segnali di ingresso e rispettivi segnali d’uscita, che rappresentano i risultati che la rete deve ottenere. Dal confronto fra i risultati effettivi e quelli desiderati (retroazione negativa), i pesi vengono progressivamente ricalibrati.

Algoritmi genetici
Gli algoritmi genetici, ispirati alle modalità evolutive degli organismi viventi, si sono imposte come un validissimo strumento per la soluzione di problemi di ottimizzazione. Il punto di partenza è la generazione casuale di una popolazione di individui, cioè di possibili soluzioni. L’adattabilità di un individuo (ovvero la bontà della soluzione che rappresenta) viene valutata secondo determinati criteri, detti di fitness.
![Identifying protein complexes with fuzzy machine learning model - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/260377604_fig2_Genetic-Algorithm-Tree-Basic-steps-of-GA-selection-crossover-and-mutation [accessed 28 Sep, 2016]](https://leganerd.com/wp-content/uploads/2016/09/Genetic-Algorithm-Tree-Basic-steps-of-GA-selection-crossover-and-mutation.jpg)
Identifying protein complexes with fuzzy machine learning model – Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/260377604_fig2_Genetic-Algorithm-Tree-Basic-steps-of-GA-selection-crossover-and-mutation [accessed 28 Sep, 2016]
Ad ogni iterazione dell’algoritmo vengono selezionati una serie di individui per il sesso computerizzato la riproduzione, che danno quindi vita a nuove possibili soluzioni. Oltre all’incrocio fra individui (crossover) che avviene con la riproduzione, essi sono anche proni a mutazioni. Una volta raggiunta una condizione di arresto, l’algoritmo seleziona l’individuo/i caratterizzati da maggior fitness – questi sono le migliori soluzioni trovate.
Swarm intelligence
L’obiettivo della swarm intelligence è sfruttare il principio – osservato nelle formiche, nei branchi di animali e negli stormi di uccelli – secondo cui dall’insieme di agenti di capacità ridotte emergono comportamenti intelligenti.

By Mehmet Karatay – Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=2179109
Un esempio particolare sono gli algoritmi detti di ant colony optimization, che mirano a risolvere problemi di ottimizzazione discreta, ispirati dal comportamento delle formiche alla ricerca di cibo. Supponiamo di voler risolvere il problema di tracciare il percorso più breve possibile fra due nodi di un grafo connesso.
Ora, ogni formica è in grado di depositare dei feromoni e di percepire la traccia dei feromoni di altre formiche. L’algoritmo quindi consiste nel marcare il nodo di arrivo del cammino come “fonte di cibo” e porre il “formicaio” in corrispondenza del nodo di partenza. Le formiche inizialmente selezionano un percorso casualmente: se seguendolo trovano la fonte di cibo, lo ripercorrono al contrario depositando feromoni.
A una successiva iterazione esse tenderanno a seguire i percorsi già marcati, ovvero che assicurano di raggiungere il cibo. Tuttavia i feromoni evaporano dopo un certo tempo, quindi più breve è il percorso, più intensa è la traccia. Dopo un adeguato numero di iterazioni le nostre formiche virtuali tenderanno a seguire unicamente il percorso più breve, reso attraente da una concentrazione di feromoni più alta.
Sintesi e simulazione di fenomeni naturali
L’obiettivo di questo secondo filone di ricerca è lo studio dei fenomeni naturali tramite la loro simulazione al calcolatore. Infatti, sviluppando sistemi che simulano la natura, è possibile testare teorie biologiche che non sarebbero altrimenti verificabili sperimentalmente.
Si identificano due principali tipi di approccio al problema: sviluppo di strumenti informatici per lo studio della geometria frattale della natura o metodi di artificial life, cioè il tentativo di riprodurre artificialmente le caratteristiche degli esseri viventi.

Rappresentazione di automi cellulari – Jonathan McCabe https://www.flickr.com/photos/jonathanmccabe/sets (fate un salto sul suo Flickr, ci sono molti lavori interessanti di computer-art)
E qui, per ragioni di spazio, vi rimando all’articolo di Aner89 per approfondire questi argomenti.

Computazione con materiali naturali
In accordo con la legge di Moore il numero di transistor, e quindi la potenza di calcolo, dei moderni chip è circa raddoppiato ad ogni anno, dal 1965. Questo grazie all’estrema miniaturizzazione dei transistor a silicio. Tuttavia ci si sta avvicinando sempre più ad un grande limite fisico.
Infatti, scendendo sotto determinate dimensioni, i transistor generano interferenze quantistiche – di fatto rendendo inutilizzabile il chip. Da qui la motivazione per seguire strade di ricerca alternative, come i circuiti basati sulla Teoria del Caos, o tecniche di calcolo sfruttando materiali naturali.
DNA computing
Questo ambito di ricerca è stato concretizzato per la prima volta da Leonard Adleman nel suo articolo del 1994 (vedi [3]). In esso Adleman dimostrò che era possibile risolvere (una piccola istanza de) il problema di trovare un cammino Hamiltoniano fra due dati vertici ([latex]v_{in}[/latex] e [latex]v_{out}[/latex]) in un grafo orientato utilizzando unicamente molecole di DNA.
Questo è un problema NP-completo, cioè per cui non è possibile trovare un algoritmo risolutivo che impiega un tempo polinomiale nella dimensione del problema e a cui possono essere ridotti tutti i problemi NP.
il lavoro di Adleman
Per prima cosa, Adleman codificò i vertici del problema con altrettanti singoli filamenti composti da 20 nucleotidi. Poi, tramite reazione a catena della polimerasi (PCR per gli amici), ne creò un gran numero di copie. Dato questo materiale di partenza, seguì poi il seguente algoritmo:
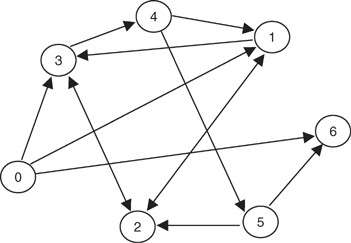
- genera casualmente cammini nel grafo: usò la ligasi per connettere le molecole di DNA;
- seleziona solo i cammini che iniziano con [latex]v_{in}[/latex] e terminano con [latex]v_{out}[/latex]: tramite PCR moltiplicò solo i cammini con questa caratteristica e poi procedette a filtrarli;
- se il grafo ha n vertici, tieni solo i cammini che ne toccano n: tramite elettroforesi su gel identificò solo le molecole composte da 7 sequenze di 20 nucleotidi;
- tieni solo i cammini che toccano tutti i vertici almeno una volta: testò i cammini utilizzando le sequenze complementari a quelle che codificavano i vertici;
- se rimangono dei cammini il problema ha soluzione, altrimenti no: tramite PCR moltiplicò il prodotto del punto 4. e con l’elettroforesi analizzò i rimanenti cammini.
Il lavoro di Adleman ha dimostrato che il DNA computing è in grado di risolvere problemi intrattabili per un computer in un tempo lineare nel numero di operazioni di laboratorio. Si deve però prendere questo risultato con cautela: il numero di filamenti di DNA che bisogna creare è nell’ordine di n!.
Quindi non è possibile trattare problemi di grandi dimensioni: per un grafo con 200 nodi sarebbero necessari [latex]3\cdot10^{25}[/latex] Kg di DNA [2] (circa dieci volte tanto il peso della terra).
Conclusione
Dalla somma di tutti questi esempi si possono trarre alcune conclusioni. Innanzitutto, il natural computing non è semplicemente un’alternativa ai classici metodi dell’Informatica.
In molti casi infatti ha reso possibile trovare la soluzione a problemi inattaccabili dai metodi tradizionali. D’altro canto, però, non sempre il natural computing si rivela la strada migliore. Per riassumere, vediamo allora quali sono i problemi e le situazioni in cui il natural computing si rivela competitivo.
- problemi complessi, caratterizzati cioè da un grande numero di variabili, di possibili soluzioni, da grande dinamicità o non-linearità;
- problemi per cui non è possibile garantire l’ottimalità di una soluzione, ma è possibile confrontare le soluzioni fra loro;
- problemi difficilmente modellabili, come ad esempio il riconoscimento di pattern e la classificazione di immagini;
- problemi per cui è necessario modellare fenomeni e forme della natura, per cui ad esempio la geometria Euclidea non si rivela adeguata.
Date le potenzialità di queste tecniche, il natural computing è un settore in continua espansione e possiamo aspettarci continui risultati e miglioramenti.
Ci sarebbe ancora molto altro da dire e tantissimi esempi da descrivere; ma se l’avessi fatto non credo stareste leggendo la conclusione. Spero di avervi fatto incuriosire e che deciderete di approfondire questo argomento a mio avviso davvero interessante.
[1] Leandro Nunes de Castro. Fundamentals of natural computing: an overview. 2006. (pdf)
[2] C.S. Calude, G. Paun, M. Tataram. A glimpse into natural computing. 1999. (pdf)
[3] Leonard M. Adleman. Molecular computation of solutions to combinatorial problems. 1994. (pdf)
[4] D. Corne, K. Deb, J.D. Knowles, X. Yao.Selected Applications of Natural Computing.
[5] L. Kari, G. Rozenberg.The many facets of natural computing. 2008. (pdf)
[6] W.S. McCulloch, W. Pitts. A logical calculus of the ideas immanent in nervous activity. 1943. (pdf)
[7] M. Fischetti. Lezioni di Ricerca Operativa. Libreria Progetto Padova, 2014.
[8] K.M. Passino. Biomimicry for Optimization, Control, and Automation. Springer, 2005.
[9] C.A. Lazere, D.E. Shasha. Natural Computing: DNA, Quantum Bits, and the Future of Smart Machines. W.W. Norton & Company, 2010.






