




È stato messo a punto da Facebook Rosetta, un sistema basato sul machine learning in grado di comprendere le scritte nelle foto e collocarle nel giusto contesto in base all’immagine rappresentata.
Facebook si trova ogni giorno sommerso da fotografie contenenti testo, e riuscire a identificarne il contenuto in modo contestualizzato è una sfida tecnologica non da poco.
L’obiettivo è migliorare la ricerca di foto, rendere più accessibile la piattaforma per chi ha impedimenti visivi, e identificare con maggior precisione i contenuti inappropriati.
Chiaramente c’era la necessità di un sistema automatizzato e non di un controllo manuale, visto il miliardo di contenuti visivi quotidiani che invadono il social.
Qui entra in gioco Rosetta, che estrapola il testo dal contenuto e lo fornisce come input ad un modello di riconoscimento del testo allenato ad identificare insieme il contesto del testo e dell’immagine.
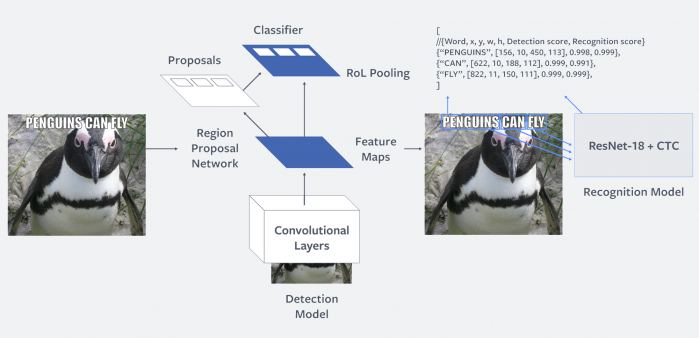
Architettura a due step.
Il riconoscimento del testo è effettuato in due step: prima c’è la sua identificazione all’interno dell’immagine, e successivamente il riconoscimento per capire le parole scritte.
Non si tratta in realtà di una pensata rivoluzionaria, ma Facebook ha il merito di averla realizzata in modo efficace, soprattutto grazie alle enormi risorse di cui dispone.
Sono proprio quelle risorse infatti che rendono possibile esaminare quella quantità infinita di materiale, peraltro con testi in svariate lingue.
Di seguito il link al post con i dettagli tecnici:





