Come è nato e come funziona il progetto reCAPTCHA
Quanti di voi hanno dovuto riempire qualche tipo di modulo via web dove viene chiesto di leggere una sequenza distorta di caratteri come questa? Quanti di voi l’hanno trovato molto, molto irritante? Ecco, l’ho inventata io. O almeno ero una delle persone che lo ha fatto.
Luis von Ahn, uno degli inventori del tanto odiato sistema “CAPTCHA” (“Completely Automated Public Turing test to tell Computers and Humans Apart”) ci racconta come è nato questo sistema e, soprattutto, come la sua società sia riuscita ad imporre prima uno standard usato da milioni di siti su internet e poi ad evolvere ulteriormente l’idea in una maniera incredibile, inventandosi di utilizzare questo metodo di controllo utente per un fine ancora migliore: Un aiuto umano collaborativo online ai sistemi di riconoscimento testuale (OCR).
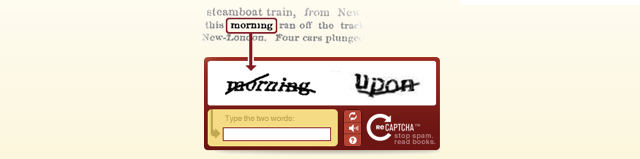
In pratica nei suoi blocchi di testo illeggibili reCAPTCHA inserisce due blocchi: uno serve al normale controllo anti bot, mentre il secondo è in realtà un blocco di testo non correttamente interpretato da un OCR: saranno gli utenti online ad interpretare quel testo e l’unione delle migliaia e migliaia di interpretazioni darà la soluzione giusta.
Quello che potreste non sapere è che oggi mentre digitate un CAPTCHA, non solo vi state identificando come essere umano, ma oltre a questo, di fatto, ci state aiutando a digitalizzare libri.
Il progetto (e relativa società) reCAPTCHA ha avuto un successo tale da essere acquisito da Google e impiegato ora attivamente nella digitalizzazione di milioni di libri all’interno del progetto Google Books.
Un bellissimo video da vedere per intero. Di seguito è presente anche la sua trascrizione per chi avesse problemi con l’inglese o non potesse vedere il video.
[more]
–
Quanti di voi hanno dovuto riempire qualche tipo di modulo via web dove viene chiesto di leggere una sequenza distorta di caratteri come questa? Quanti di voi l’hanno trovato molto, molto irritante? Ok, notevole. L’ho inventata io. (Risate) O almeno ero una delle persone che lo ha fatto.
Quella cosa si chiama CAPTCHA. E il motivo per cui è lì è assicurarsi è che voi, l’entità che sta riempiendo il modulo, sia realmente un essere umano e non un programma scritto per inviare il modulo milioni e milioni di volte. Il motivo per cui funziona è perché gli esseri umani, almeno gli umani che non hanno problemi di vista, non hanno problemi a leggere questi caratteri ondulati e distorti, mentre un programma di computer non lo può fare altrettanto bene. Quindi per esempio, nel caso di Ticketmaster, il motivo per cui dovete digitare questi caratteri distorti è prevenire che i bagarini scrivano un programma che possa comprare milioni di biglietti, due alla volta.
I CAPTCHA vengono utilizzati ovunque su Internet. E considerato che sono utilizzati così di frequente, tante volte la sequenza precisa di caratteri casuali mostrata all’utente non è così fortunata. Questo è un esempio dalla pagina di registrazione di Yahoo. I caratteri casuali che sono capitati all’utente sono stati A,T,T,E,N,D,I, che ovviamente scandiscono una parola. Ma la parte migliore è il messaggio che il servizio clienti di Yahoo ha ricevuto 20 minuti dopo. Testo:”Aiuto! Sto aspettando da più di 20 minuti e non succede niente.” (Risate) Questa persona ha pensato di dover aspettare. Certo, questo poveraccio non è messo tanto bene.
(Risate)
Il progetto CAPTCHA è una cosa che abbiamo creato qui al Carnegie Mellon più di 10 anni fa, e viene utilizzata ovunque. Lasciate che ora vi racconti del progetto che abbiamo seguito qualche anno dopo, che è l’evoluzione del CAPTCHA. È un progetto che chiamiamo reCAPTCHA, ed è una cosa che abbiamo iniziato qui al Carnegie Mellon, e che poi abbiamo trasformato in startup. E poi circa un anno e mezzo fa, Google ha acquistato la società.
Fatemi spiegare che cosa ha dato il via questo progetto. Questo progetto nasce dalla seguente constatazione: che circa 200 milioni di CAPTCHA vengono digitati ogni giorno dalla gente in tutto il mondo. Quando l’ho sentito, mi sono sentito fiero di me stesso. Ho pensato, guarda che impatto ha avuto la mia ricerca. Ma poi ho cominciato a sentirmi male. Ecco perché, ogni volta che digitate un CAPTCHA, sostanzialmente sprecate 10 secondi del vostro tempo. E se lo moltiplicate per 200 milioni, ottenete che l’umanità intera spreca circa 500 000 ore ogni giorno a digitare questi fastidiosi CAPTCHA. Allora ho cominciato a sentirmi male.
(Risate)
E poi ho cominciato a pensare, certo, non possiamo sbarazzarci dei CAPTCHA, perché la sicurezza del Web in qualche modo ne dipende. Ma poi ho cominciato a pensare, c’è un modo di usare questo sforzo per qualcosa che sia buono per l’umanità? Vedete, ecco qui. Mentre digitate un CAPTCHA, durante questi 10 secondi, il vostro cervello sta facendo qualcosa di straordinario. Sta facendo quello che un computer non può ancora fare. Possiamo portarvi a fare un lavoro utile in questi 10 secondi? Si può metterla in altro modo, c’è qualche problema enorme che non riusciamo ancora a far risolvere ai computer, e che possiamo spezzare in pezzetti da 10 secondi così che ogni volta che qualcuno risolve un CAPTCHA risolve un piccolo pezzo di questo problema? E la risposta è “si”, ed ecco cosa stiamo facendo ora.
Quello che potreste non sapere è che oggi mentre digitate un CAPTCHA, non solo vi state identificando come essere umano, ma oltre a questo, di fatto, ci state aiutando a digitalizzare libri. Fatemi spiegare come funziona. Ci sono tantissimi progetti che cercano di digitalizzare libri. Google ne segue uno. The Internet Archive ne ha uno. Amazon, ora con il Kindle, sta cercando di digitalizzare libri. Sostanzialmente funziona in questo modo: si comincia con un vecchio libro. Avete visto queste cose, vero? Un libro? (Risate) Cominciate con un libro, lo scannerizzate.
Scannerizzare un libro è come scattare una foto digitale di ogni singola pagina. Vi dà un’immagine di ogni singola pagina del libro. Questa è un’immagine con testo di ogni pagina del libro. Il passo successivo del processo è che il computer deve essere in grado di decifrare tutte le parole in questa immagine. Lo si fa usando una tecnologia chiamata OCR, per il riconoscimento ottico dei caratteri, che scatta una foto del testo e cerca di decifrarlo. Il problema è che l’OCR non è perfetto. Specialmente per i libri più vecchi dove l’inchiostro è sbiadito e le pagine sono ingiallite, l’OCR non riesce a riconoscere tante parole. Per esempio, per cose che sono state scritte più di 50 anni fa, il computer non riesce a riconoscere circa il 30% delle parole. Quindi quello che facciamo ora è prendere tutte le parole che il computer non riesce a riconoscere e far sì che le persone le leggano per noi mentre digitano un CAPTCHA su Internet.
Quindi la prossima volta che digitate un CAPTCHA, queste parole che state digitando sono in realtà parole che provengono da libri che sono stati digitalizzati che il computer non è riuscito a riconoscere. E il motivo per cui oggi ci sono due parole invece di una è perché, sapete, una delle parole è una parola che il sistema ha tirato fuori da un libro, e che non sapeva cosa fosse, e ve la sottopone. Ma siccome non sa la risposta, non può valutarla. Quindi quello che facciamo è assegnarvi un’altra parola, di cui il sistema conosce la risposta. Non vi diciamo quale delle due, e vi chiediamo di digitarle entrambe. E se digitate la parola giusta per quella di cui il sistema conosce già la risposta, suppone che siate umani, ed è abbastanza fiducioso che abbiate digitato l’altra parola correttamente. E se ripetete questo processo per 10 persone diverse e tutte sono d’accordo su qual è la parola nuova, si ottiene un’altra parola digitalizzata correttamente.
Quindi il sistema funziona in questo modo. E sostanzialmente, da quanto l’abbiamo rilasciato circa 3 o 4 anni fa, tantissimi siti hanno cominciato a passare dal vecchio CAPTCHA dove la gente buttava via il tempo al nuovo CAPTCHA dove la gente aiuta a digitalizzare libri. Per esempio, Ticketmaster. Ogni volta che comprate biglietti con Ticketmaster, aiutate a digitalizzare un libro. Facebook: Ogni volta che aggiungete un amico o fate un poke a qualcuno, aiutate a digitalizzare un libro. Twitter e circa 350 000 altri sisti usano tutti reCAPTCHA. E in realtà, il numero di siti che usano reCAPTCHA è così alto che il numero di parole che digitalizziamo ogni giorno è davvero enorme. Sono circa 100 milioni al giorno, che equivale a circa 2,5 milioni di libri all’anno. E viene tutto fatto una parola alla volta solo grazie a persone che digitano CAPTCHA su Internet.
(Applausi)
Ora naturalmente, visto che facciamo così tante parole al giorno, capitano cose divertenti. E questo è vero anche perché diamo alle persone due parole inglesi casuali una accanto all’altra. Possono capitare cose divertenti. Per esempio, abbiamo presentato questa parola. È la parola “Cristiani”; non c’è niente di sbagliato. Ma se la presentate insieme ad un’altra parola casuale, possono capitare cose brutte. Otteniamo questo. (Testo: cattivi cristiani) Ma è anche peggio, perché il sito dove veniva mostrato in realtà si chiamava Ambasciata del Regno di Dio. (Risate) Ops. (Risate) Eccone un’altro bruttissimo. JohnEdwards.com (Testo: Dannato liberale) (Risate) Continuiamo a insultare la gente a destra e a sinistra ogni giorno.
Naturalmente, non stiamo solo insultando persone. Vedete, da quando proponiamo due parole scelte casualmente, possono capitare cose interessanti. In realtà tutto questo ha dato luogo ad un grande fenomeno su Internet a cui hanno partecipato migliaia di persone, che si chiama CAPTCHA art. Sono sicuro che qualcuno di voi ne ha sentito parlare. Ecco come funziona. Immaginate di utilizzare Internet e vedete un CAPTCHA che pensate sia peculiare, come questo CAPTCHA. (Testo: tostapane invisibile) Tutto quello che dovete fare è catturare la schermata. Poi naturalmente, inserite il CAPTCHA perché ci aiutate a digitalizzare un libro. Ma poi, prima catturate la schermata, e poi disegnate qualcosa che abbia un nesso. (Risate) Ecco come funziona. Ce ne sono decine di migliaia. Qualcuno è veramente delizioso. (Testo: afferrato) (Risate) Qualcuno è divertente. (Testo: fondatori impietriti) (Risate) E qualcuno, come “certezza paleontologica”, contiene Snoop Dogg.
(Risate)
Ok, questo è il mio numero preferito di reCAPTCHA. Questa è la cosa che preferisco di questo progetto. Questo è il numero di utenti unici che hanno aiutato a digitalizzare almeno una parola di un libro con reCAPTCHA: 750 milioni, che è un po’ più del 10% della popolazione mondiale, che ci ha aiutato a digitalizzare le conoscenze dell’uomo. E sono numeri come questi che danno la motivazione per pianificare la mia ricerca. La domanda che motiva la mia ricerca è la seguente: Se guardate le conquiste dell’umanità su larga scala, sono cose veramente grandi che l’umanità ha fatto e messo insieme storicamente — come per esempio, costruire le piramidi d’Egitto o il Canale di Panama o mandare l’uomo sulla luna — c’è un fatto curioso riguardo a queste imprese, cioè che sono state realizzate con circa lo stesso numero di persone. È strano; tutte sono state fatte con circa 100 000 persone. E il motivo è che, prima di Internet, coordinare più di 100 000 persone, senza contare la remunerazione, era sostanzialmente impossibile. Ma ora con Internet, vi ho appena mostrato un progetto dove abbiamo coinvolto 750 milioni di persone per aiutare a digitalizzare la conoscenza umana. Quindi la domanda che motiva la mia ricerca è, se possiamo mandare l’uomo sulla luna con 100 000 persone, cosa possiamo fare con 100 milioni?
Basandomi su questa domanda, abbiamo avuto tanti progetti diversi su cui abbiamo lavorato. Fatemi raccontare di uno dei progetti che più mi esalta. È una cosa su cui abbiamo lavorato silenziosamente nell’ultimo anno e mezzo o giù di lì. Non è ancora stato lanciato. Si chiama Duolingo. Visto che non è ancora stato lanciato, shhhh! (Risate) Sì, mi fido di voi. Questo è il progetto. Ecco come è cominciato. È cominciato quando ho posto una domanda a un mio studente laureando, Severin Hacker. Ok, questo è Severin Hacker. Allora, ho fatto una domanda al mio studente. A proposito, mi avete sentito bene; il suo cognome è Hacker. Allora, gli ho fatto questa domanda: Come riusciamo a portare 100 milioni di persone a tradurre il Web in tutte le principali lingue gratuitamente?
Ok, ci sono molte cose da dire su questa domanda. Prima di tutto, tradurre il Web. Oggi il Web si divide in molte lingue diverse. Una larga parte è in Inglese. Se non sapete l’Inglese, non potete accedervi. Ma una larga parte è in altre lingue, e se non sapete queste lingue, non potete avere accesso. Vorrei quindi tradurre tutto il Web, o almeno la maggior parte del Web, in tutte le principali lingue. Quindi questo è quello che vorrei fare.
Qualcuno di voi potrebbe dire, perché non possiamo usare i computer per tradurlo? Perché non possiamo usare la traduzione automatica? La traduzione automatica odierna sta cominciando a tradurre alcune frasi qua e là. Perché non possiamo usarla per tradurre tutto il Web? Il problema è che non ancora abbastanza accurata e probabilmente non lo sarà per il prossimi 15 o 20 anni. Fa molti errori. Anche quando non fa errori, visto che fa così tanti errori, non sai mai se fidarti o meno.
Fatemi fare un esempio di una cosa che è stata tradotta con un computer. In realtà è un post in un forum. È qualcuno che stava cercando di chiedere una cosa su JavaScript. È stato tradotto dal Giapponese all’Inglese. Vi lascio leggere. Questa persona comincia a scusarsi per il fatto che è tradotto con un computer. La frase successiva sarà il preambolo alla domanda. Sta solo spiegando qualcosa. Ricordatevi, è una domanda su JavaScript. (Testo: Spesso, il tempo-capra installa un errore è vomito). (Risate) Poi arriva la prima parte della domanda. (Testo: Quante volte come il vento, un palo, e il drago?) (Risate) Poi arriva la mia parte preferita della domanda. (Testo: Questo insulto alle pietre del padre?) (Risate) E poi arriva la fine, che è il mio pezzo preferito. (Testo: Per favore perdonami per la tua stupidità. Ci sono molti grazie.) (Risate) Ok, quindi la traduzione automatica, non è ancora abbastanza buona. Tornando alla domanda.
Abbiamo bisogno di persone che traducano tutto il Web. La prossima domanda che potreste farmi è, perché non si possono semplicemente pagare le persone per farlo? Potremmo pagare traduttori professionisti per tradurre tutto il Web. Potremmo farlo. Sfortunatamente, sarebbe estremamente costoso. Per esempio la traduzione di una piccolissima frazione del Web, Wikipedia, in un’altra lingua, lo Spagnolo. Wikipedia esiste in Spagnolo, ma è molto piccola rispetto all’Inglese. È circa il 20% di quella inglese. Se volessimo tradurre il restante 80% in Spagnolo, costerebbe almeno 50 milioni di dollari — e questo anche al costo del paese più competitivo che ci sia. Quindi sarebbe molto costoso. Quello che vogliamo fare è portare 100 milioni di persone a tradurre il Web in tutte le principali lingue gratuitamente.
Se questo è quello che volete fare, vi accorgete rapidamente che andrete incontro a due ostacoli, due grossi ostacoli. Il primo è la carenza di persone bilingui. Non so neanche se esistano 100 milioni di persone là fuori che usano il Web abbastanza bilingui da aiutarci a tradurre. È un grosso problema. L’altro problema con cui vi scontrerete è la mancanza di motivazione. Come riusciremo a motivare le persone a tradurre veramente il Web gratuitamente? Normalmente, si pagano persone per farlo. Come faremo a motivarle per farlo gratuitamente? Quando abbiamo cominciato a pensarci, ci siamo bloccati a causa di queste due cose. Ma poi ci siamo resi conto che in realtà c’è un modo per risolvere entrambi i problemi con la stessa soluzione. C’è un modo per prendere due piccioni con una fava. Ed è trasformare la traduzione di una lingua in qualcosa che milioni di persone vogliono fare, e che risolve anche il problema della carenza di bilingui, ed è l’apprendimento della lingua.
Abbiamo scoperto che oggi ci sono più di 1,2 miliardi di persone che imparano una lingua straniera. La gente vuole veramente imparare una lingua straniera. E non solo perché sono costrette a farlo a scuola. Per esempio, solo negli Stati Uniti, ci sono più di cinque milioni di persone che hanno pagato più di 500$ in software per imparare una lingua. La gente vuole quindi davvero imparare una nuova lingua. Quindi quello su cui abbiamo lavorato l’ultimo anno e mezzo è un nuovo sito web — si chiama Duolingo — dove l’idea di base è che la gente impara una nuova lingua gratuitamente mentre contemporaneamente traduce il Web. E quindi sostanzialmente si impara facendo.
Funziona in questo modo, se siete principianti, vi diamo delle frasi molto, molto semplici. Ovviamente nel Web ci sono tantissime frasi semplici. Vi diamo frasi molto, molto semplici insieme al significato di ciascuna parola. E mentre le traducete e vedete come le traducono altre persone, cominciate a imparare la lingua. E man mano che migliorate vi diamo frasi sempre più complesse da tradurre. Ma in ogni momento, imparate facendo.
La cosa pazzesca di questo metodo è che funziona veramente. Prima di tutto, la gente impara veramente una lingua. Abbiamo quasi finito di costruirlo e lo stiamo testando. La gente può veramente impararci una lingua. E la imparano bene quanto potrebbero fare con il miglior software di lingue. La gente impara quindi veramente una lingua. E non solo imparano, ma la cosa è ancora più interessante. Perché con Duolingo, la gente impara con contenuti reali. Contrariamente all’apprendimento con frasi precostruite, la gente impara con contenuti reali, il che è realmente interessante. Quindi la gente impara veramente una lingua.
Ma la cosa ancora più sorprendente è che le traduzioni che riceviamo dalla gente che usa il sito, anche se sono solo principianti, le traduzioni che riceviamo sono accurate quanto quelle di traduttori professionisti, il che è veramente sorprendente. Lasciate che vi mostri un esempio. Questa è una frase tradotta dal Tedesco all’Inglese. In alto c’è il Tedesco. In mezzo la traduzione in Inglese fatta da un traduttore inglese professionista che abbiamo pagato 20 centesimi a parola per la traduzione. E in basso la traduzione degli utenti di Duolingo, nessuno dei quali sapeva il Tedesco prima di iniziare a usare il sito. Potete vedere, è praticamente perfetta. Ora ovviamente c’è un trucco qui per rendere le traduzioni buone quanto quelle di traduttori professionisti. Combiniamo le traduzioni di più principianti per ottenere la qualità di un singolo traduttore professionista.
Anche se stiamo combinando le traduzioni, il sito in realtà può tradurre abbastanza rapidamente. Lasciate che vi mostri, questa è la nostra stima sulla velocità a cui potremmo tradurre Wikipedia dall’Inglese allo Spagnolo. Ricordatevi, un costo di 50 milioni di dollari. Quindi se volessimo tradurre Wikipedia in Spagnolo, potremmo farlo in cinque settimane con 100 000 utenti attivi. E potremmo farlo in circa 80 ore con un milione di utenti attivi. Visto che tutti i progetti su cui ha lavorato il mio gruppo fin’ora hanno avuto milioni di utenti, siamo fiduciosi che saremo in grado di tradurre molto rapidamente con questo progetto.
La cosa che più mi emoziona di Duolingo è che credo fornisca un corretto modello di business per l’apprendimento delle lingue. Quindi ecco il punto: Il modello di business corrente per l’apprendimento delle lingue è che gli studenti paghino, e in particolare, lo studente paga 500 dollari per RosettaStone. (Risate) Questo è il modello di business corrente. Il problema con questo modello di business è che il 95% della popolazione mondiale non ha 500 dollari. Quindi è estremamente ingiusto nei confronti dei poveri. È completamente sbilanciato a favore dei ricchi. Invece guardate, in Duolingo siccome mentre imparate di fatto create valore, state traducendo testi — che per esempio, potrebbe essere assegnata a qualcuno per la traduzione. Quindi ecco come potremmo monetizzare. Visto che la gente crea valore mentre impara, non deve pagare con denaro, bensì con il proprio tempo. Ma la magia qui è che pagano con il loro tempo, ma quello è tempo che avrebbero comunque dedicato ad imparare la lingua. La cosa bella di Duolingo è che credo fornisca un modello di business equo — che non discrimina le persone povere.
Ecco qua il sito. Grazie. (Applausi) Ecco qua il sito. Non l’abbiamo ancora lanciato, ma se volete, potete iscrivervi per fare parte della versione beta, che partirà tra 3 o 4 settimane. Non abbiamo ancora lanciato Duolingo.
A proposito, io sono quello che ne parla, ma in realtà Duolingo è il lavoro di un gruppo fantastico, alcuni sono qui. Quindi grazie.
(Applausi)
–
[/more]
– Luis von Ahn: Massive-scale online collaboration (ted.com)
– Sito ufficiale reCAPTCHA (google.com)
PS by @Zed epic gag by Dork Tower:
[more]

[/more]